


24. Validar el HTML
Mark Norman Francis. 26 de septiembre de 2008. Última modificación: 13 de marzo de 2017 (equipo docente del grado de Multimedia). Publicado en: estándares, web, w3c, html, validador
Ahora ya habéis escrito unas cuantas páginas en HTML y parece que se ven bastante bien, pero hay unas cuantas cosas que no son del todo correctas. ¿Cuál es la mejor manera de encontrar aquello que no funciona y garantizar que estas páginas (y todas las páginas que escribáis en el futuro) se vean correctamente con todos los navegadores sin ningún error?
La respuesta es la validación. Hay muchas herramientas disponibles, del W3C y de otros sitios, que os permiten validar el código de vuestros sitios web. Los tres validadores más habituales que utilizaréis son:
El validador de marcado del W3C: Busca el doctype del (X)HTML que utilizáis para el documento que le dais para comprobar, revisa todo el documento y señala los lugares donde el HTML no sigue correctamente el doctype (es decir, donde hay errores en el HTML).
El comprobador de enlaces de W3C: Esta herramienta revisa todo el documento que le deis para comprobar y prueba todos los enlaces que encuentra para garantizar que funcionen (es decir, que los valores href no apunten hacia recursos que no existen).
El validador del CSS de W3C: Tal como probablemente ya os imagináis, esta herramienta revisa un documento CSS (o HTML/CSS) y comprueba que el CSS siga correctamente las especificaciones del CSS.
En este apartado explicaremos el primero de estos tres validadores y la manera de utilizarlo y cómo interpretar los tipos de resultados típicos que da. El comprobador de enlaces es muy obvio, y sobre el validador del CSS no habrá que explicar mucho nada más una vez que hayáis leído este apartado y los apartados relativos al CSS que encontraréis más adelante en este curso.
Ved también
Podéis ver los contenidos del módulo "CSS" de este curso.
Los contenidos de este apartado son los siguientes:
- 24.1. Errores
- 24.2. ¿Qué es la validación?
- 24.3. ¿Por qué validar?
- 24.4. Los diferentes navegadores interpretan el HTML no válido de una manera diferente
- 24.4.1. El "quirks mode"
- 24.5. Cómo validar las páginas
- 24.5.1. El validador de HTML del W3C
- Resumen
- Preguntas de repaso
- Otras herramientas que podéis utilizar
24.1. Errores
En general, en la programación informática hay dos tipos de problemas con el código:
Errores sintácticos, que se dan cuando un error de escritura del código hace que el ordenador sea incapaz de ejecutar o compilar el programa adecuadamente.
Errores de programación (o lógicos), que se dan cuando el código no refleja completamente la intención del programador.
La mayoría de los lenguajes de programación detectan muy fácilmente el primer error, ya que el programa no se ejecuta o no se compila hasta que se soluciona. Esto provoca que encontrar y solucionar estos tipos de problemas en los momentos de desconcierto en los que os preguntáis: "¿por qué no hace lo que debería hacer?" sea mucho más fácil.
HTML no es un lenguaje de programación. Los errores de sintaxis de una página web no hacen normalmente que el navegador web se niegue a abrir la página (a pesar de que XHTML suele ser más estricto que HTML, por lo menos cuando se sirve como datos application/xhtml+xml o text/xml, según se quiera; y algunos doctypes rechazarán el uso de ciertos tipos de elementos HTML). Ésta es una de las razones principales de la rápida adopción y difusión de la web.
El primer navegador web, WorldWideWeb (creado por Tim Berners-Lee) era también un editor, y permitía crear páginas web sin tener que aprender HTML. Este editor creaba HTML no válido. Esto se podría haber solucionado, pero estableció un precedente importante que aún existe en todos los navegadores web actuales: es más importante que la gente pueda acceder al contenido que quejarse de errores que la gente no entenderá o que no podrá solucionar.
24.2. ¿Qué es la validación?
Los navegadores web aceptarán las páginas web malas (el término que utilizamos aquí es "no válidas") y harán todo lo que puedan para reproducir el código intentando adivinar cuáles eran las intenciones del autor, pero también se puede comprobar si el HTML se ha escrito correctamente; de hecho, tal como veréis a continuación, vale la pena hacerlo. Eso se conoce como "validar" el HTML.
El programa de validación compara el código HTML de la página web con las normas de su doctype y dice si no se han respetado estas normas y dónde.
Ved también
Podéis ver el doctype en el apartado 14 del módulo "Fundamentos de HTML".
24.3. ¿Por qué validar?
Algunos desarrolladores de webs opinan que si una página web se ve bien en los navegadores, el hecho de que no se valide no tiene ninguna importancia. Consideran que la validación es un objetivo ideal, pero ni mucho menos, obligatorio.
Esta actitud no deja de ser sabia. La especificación HTML no es perfecta, y ahora incluso ha quedado un poco anticuada. Algunos detalles que son perfectamente correctos (como por ejemplo empezar una lista ordenada en un punto diferente de 1) no son válidas en HTML.
Ved también
Podéis ver cómo empezar una lista ordenada en un punto diferente de 1 en el apartado 16 de este módulo.
Sin embargo, tal como dice el dicho:
"Aprende las normas para así saber cómo infringirlas correctamente."
Hay dos razones muy potentes para validar el HTML mientras lo vais escribiendo.
Las personas no son perfectas, igual que tampoco lo es el código; todos cometemos errores, y vuestras páginas web serán de una calidad superior (es decir, funcionarán mejor) si los elimináis.
Los navegadores cambian. En el futuro es muy probable que los navegadores sean menos condescendientes cuando analicen un código no válido, y no al revés.
La validación es vuestro sistema de alerta precoz ante la introducción de problemas en vuestras páginas que entonces se pueden manifestar de maneras realmente interesantes y difíciles de determinar. Cuando un navegador encuentra código HTML no válido, debe tomar una decisión bien fundamentada sobre cuáles eran vuestras intenciones, y los diferentes navegadores pueden llegar a respuestas diferentes.
24.4. Los diferentes navegadores interpretan el HTML no válido de una manera diferente
El HTML válido es el único contrato que tenéis con los fabricantes de los navegadores. La especificación de HTML dice cómo lo deberíais escribir vosotros y cómo deberían interpretar vuestro documento los navegadores. Actualmente, la conformidad de los navegadores con los estándares ha llegado al punto en el que, si escribís un código válido, todos los navegadores principales interpretarán vuestro código de la misma manera. Con el HTML eso sucede prácticamente siempre, mientras que los demás estándares se pueden encontrar con algunas otras diferencias aquí y allí con respecto a su aceptación.
Pero ¿qué sucede si enviáis un código no válido a un navegador? ¿Qué consecuencias tiene? La respuesta es que entra en acción la gestión de errores del navegador para decidir qué hay que hacer con el código. Básicamente, lo que hace es decir: "De acuerdo, este código no se puede validar, pero ¿cómo podemos presentar esta página al usuario final? Llenaremos los huecos de la manera siguiente".
Suena muy bien, ¿no? Si la página contiene algunos errores, ¿el navegador llenará los huecos por vosotros? Pues no exactamente, porque cada navegador hace las cosas a su manera. Por ejemplo:
<p><strong>Este texto debería estar en negrita</p>
<p>¿Este texto debería estar en negrita? ¿Cómo queda el HTML cuando
se representa?</p>
<p><a href="#"></strong>Este texto debería ser un enlace</p>
<p>¿Este texto debería ser un enlace? ¿Cómo queda el HTML cuando se
representa?</p>Los errores son que el elemento strong se encuentra anidado incorrectamente a través de múltiples elementos de bloque y que el elemento de ancla no se ha cerrado. Cuando se intenta verlo con diferentes navegadores, éstos interpretan el código de maneras muy diferentes:
Opera convierte los elementos consecutivos en hijos del elemento negrita.
Firefox añade elementos negrita adicionales entre los párrafos que no estaban presentes en el etiquetado.
Internet Explorer pone el texto "Este texto debería ser un enlace" fuera de la etiqueta de ancla que crea el enlace.
Nota
Podéis encontrar la versión original de este ejemplo en el artículo de Hallvord Steen "Same DOM errors, different browser interpretations"; si lo leéis, encontraréis un tratamiento mucho más detallado de los errores del HTML e información sobre las herramientas de depuración.
Ninguno de los comportamientos de los diferentes navegadores es incorrecto; todos intentan reparar los errores de vuestro código incorrecto. La conclusión es, pues, que hay que evitar siempre que sea posible el etiquetado no válido en vuestra página.
24.4.1. El "quirks mode"
Otra cosa que deberíais conocer es lo que se conoce como "Quirksmode" o "mode quirks" (peculiaridades). Es el modo al que pasa el navegador cuando encuentra una página con un doctype incorrecto, o sin doctype. En este modo, el navegador hace todo lo que puede para saber qué serie de reglas debe utilizar para validar el código y repara los errores lo mejor que sabe. Este modo existe realmente para permitir la visualización de las páginas más antiguas, y no se debe utilizar nunca para crear una página nueva.
24.5. Cómo validar las páginas
Ahora que ya hemos explorado toda la parte teórica que hay detrás de la validación del HTML, ya podemos pasar a la parte más sencilla: la validación en sí. Bien, de hecho, no es exactamente así. Poner una URL en un validador y ver si la página es válida o no es muy fácil; descubrir qué es lo que está mal y solucionar los errores no es siempre tan fácil, porque los mensajes de error en ocasiones son algo crípticos. A continuación veremos algunos ejemplos.
Lo que miraremos en este subapartado es lo siguiente (también os lo podéis descargar o ver su HTML):
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en">
<head>
<title>Validating your HTML</title>
</head>
<body>
<h2>The tale of Herbet Gruel</h2>
<p>Welcome to my story. I am a slight whisp of a man, slender and fragile,
features wrinkled and worn, eyes sunken into their sockets like rabbits
cowering in their burrows. The <em>years have not been kind to me</em>,
but yet I hold no regrets, as I have overcome all that sought to ail me,
and have been allowed to bide my time, making mischief as I travel to and
fro, 'cross the unyielding landscape of the <a href="http://outer-rim-
rocks.co.uk" colspan="3">outer rim</a>.</p>
<h3>Buster</h3>
<p>Buster is my guardian angel. Before that, he was my dog. Before that,
who knows? I lost my dog many moons ago while out hunting geese in the
undergrowth. A shot rang out from my rifle, and I called for Buster to
collect the goose I had felled. He ran off towards where the bird had
landed, but never returned. I never found his body, but I comfort myself
with the thought that he did not die; rather he transcended to a higher
place, and now watches over me, to ensure my well-being.
<h3>My possessions</h3>
<p>A travelling man needs very little to accompany him on the road:</p>
<ul>
<li>My hat full of memories</li>
<li>My trusty walking cane</li>
<li>A purse that did contain gold at one time</li>
<li>A diary, from the year 1874<li>
<li>An empty glasses case</li>
<li>A newspaper, for when I need to look busy</li>
</ul>
</body>Archivo fuente: "example_validation.html"
Esta página tan sencilla está formada por tres títulos, tres párrafos, un enlace y una lista no ordenada. Utiliza el doctype XHTML 1.0 Strict como serie de reglas de validación. El documento contiene algunos errores, que descubriréis más adelante con el validador de HTML del W3C.
24.5.1. El validador de HTML del W3C
Como ya hemos comentado, el W3C ofrece un validador en línea. Os será muy útil poder cambiar entre diferentes pestañas para ir alternando entre el validador y este apartado mientras vais siguiendo este ejemplo.
Tened en cuenta que también podéis validar páginas con el validador del W3C directamente desde el navegador Opera sencillamente haciendo clic con el botón derecho del ratón o con un "Ctrl" + clic y seleccionando la opción "Validate" (validar).
Veréis que el validador tiene tres pestañas en la parte superior del interfaz:
Validate by URI (validar por URI): permite introducir la dirección de una página que ya se encuentra en Internet para su validación.
Validate by File Upload (validar por carga de archivo): permite cargar un archivo HTML para su validación.
Validate by Direct Input (validar por entrada directa): permite pegar el contenido de un archivo HTML en la ventana para su validación.
Sea cual sea el método que utilicéis, el resultado debería ser el mismo; creemos que lo más sencillo es comprobar la página de ejemplo que tenemos aquí copiando todo el código anterior y pegándolo en una tercera pestaña. Si lo hacéis, deberíais obtener el resultado que podéis ver en la figura 1:
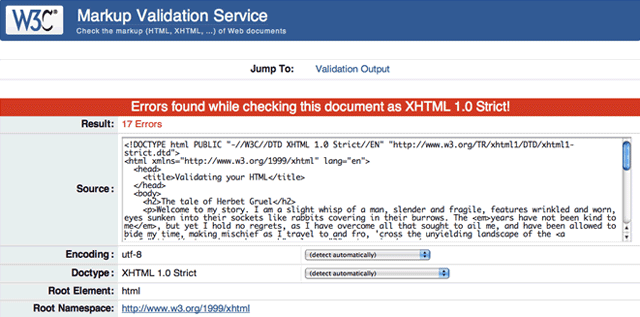
Figura 1. Resultados de la validación del documento de muestra, ¡17 errores!
Puede parecer muy preocupante, especialmente si os digo que en este documento ¡no hay realmente 17 errores! No os desesperéis; dice que hay más errores de los que hay realmente porque normalmente un error al principio de la página tiene un efecto en cascada, que hace que el validador informe de más errores a medida que va bajando por la página, ya que parece que hay más elementos que no están cerrados o que no están correctamente anidados. Sólo es necesario que penséis en el significado del mensaje de error y que encontréis los errores obvios de etiquetado. La siguiente tabla muestra todos los errores que hemos reparado para poder validar la página, junto con las deducciones para averiguar qué era lo que no funcionaba y la solución aplicada.
| Mensaje de error | Deducción | Reparación |
|---|---|---|
| Tabla 1. Los errores reparados para validar la página de ejemplo | ||
| Línea 8, columna 461: no hay ningún atributo "colspan" | Sabemos que hay un atributo colspan y que es un HTML válido; por lo tanto, ¿por qué dice que no lo hay? Esperad; quizá quiere decir que se utiliza en un elemento en el que no se debería utilizar. Evidentemente, se utiliza en un elemento a. ¡Mal! |
Hemos eliminado el atributo colspan del elemento a. |
| Línea 13, columna 7: el tipo de documento no permite el elemento "h3" aquí; falta una etiqueta de apertura de "object", "applet", "map", "iframe", "button", "ins", "del". <h3>My possessions</h3> | A primera vista también parece extraña, ya que el elemento h3 está cerrado y en este contexto está permitido. Debéis tener en cuenta que, a menudo, este mensaje de error significa que hay un elemento no cerrado cerca... |
Hemos añadido una etiqueta de cierre p a la línea que hay sobre el título en cuestión. |
| Línea 19, columna 40: el tipo de documento no permite el elemento "li" aquí; falta una etiqueta de apertura de "ul", "ol", "menu", "dir". <li>A diary, from the year 1874<li> | Éste es muy fácil; en la línea indicada podéis ver rápidamente que la etiqueta li final no tiene la barra inclinada de cierre (/) |
Hemos añadido una barra inclinada de cierre a la línea en cuestión. |
| Línea 23, columna 9: no está la etiqueta de cierre para "html", pero se ha especificado OMITTAG NO. </body> | En este caso también es muy fácil ver que falta la etiqueta html final. Incluso la explicación del mensaje de error empieza diciendo que quizá habéis olvidado cerrar un elemento. |
Hemos añadido el elemento html final que faltaba. |
Después de corregir estos errores, el validador da un mensaje bastante satisfactorio, tal como muestra la figura 2:
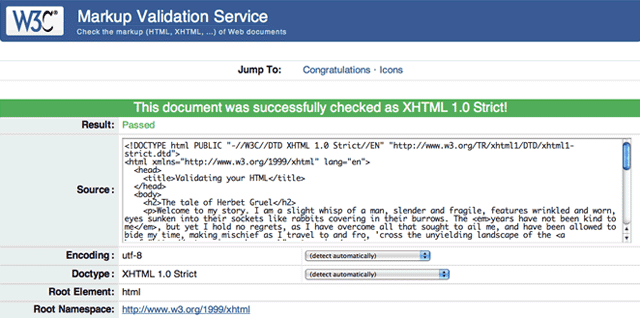
Figura 2. Un mensaje satisfactorio que dice que ya se han reparado todos los errores.
Eso es todo lo que había que hacer. Sólo necesitáis no poneros nerviosos y que recordéis el doctype que utilizáis para validar la página.
Descargaos o mirad la versión correcta del HTML en: " example_validation_fixed.html"
Resumen
Después de leer este apartado, deberíais poder trabajar con comodidad con el validador en línea de W3C para validar vuestro HTML. Esto, sin embargo, es sólo la punta del iceberg con respecto a la validación; a continuación encontraréis una lista con unas herramientas más complicadas que os pueden ayudar cuando vuestras páginas se vayan haciendo grandes y se vayan complicando.
Preguntas de repaso
¿Qué sucede cuando un navegador analiza un HTML no válido?
¿Qué problema hay?
¿El uso de un conjunto de marcos en un documento validado con el doctype HTML 4 Strict generará un error?
Otras herramientas que podéis utilizar
El menú de depuración de Opera
Bookmarklet de validación general
La extensión Web Developer de Firefox



